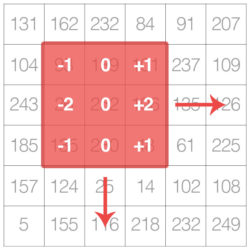
前言 换一个角度来看的话,图像其实就是一个多维矩阵。不过跟你在学校里学到的传统矩阵不一样的是,图像还有深度,即图像中的通道数。一个标准的RGB图像有3个深度,分别为红、绿、蓝3个通道。 有了上述认识后,我们就不难理解模糊、锐化、边缘检测等这些基本的图像处理,其实就是图像这个大矩阵和一个小矩阵(内核)卷积的结果这一事实了。这个小矩阵或者说是内核从原始图像左上角开始,从左到右、从上到下依次滑过图像的每一个像素点,在每个像素点处都要进行卷积运算。 通常,我们会手动定义内核,这样我们可以获得各种自己想要的图像处理函数。你可能已经很熟悉模糊(平均平滑,高斯平滑,中值滤波等)、边缘检测(拉普拉斯,Sobel,,Scharr,Prewitt等)、以及锐化操作了,其实这些操作都是通过手动定义内核来实现的。 所以问题来了,有什么办法能自主学习这些各式各样的滤波器吗?能将这些滤波器用于图像分类和目标检测吗? 答案是肯定的。 但是在那之前,我们需要先了解一点内核和卷积的知识。 内核 让我们再次想象一下,原始图像是一个大矩阵,而内核是一个很小的矩阵(相对于原始图像): 如上图所示,我们沿着原始图像,让内核从左到右、从上到下滑动。 在原始图像的每个(X,Y)坐标像素点处,内核中心点与该像素点重合,原始图像(X,Y)坐标周围与内核重合的像素点区域,与内核区域做卷积运算,得到一个输出值。这个输出值将被存储在输出图像中的(X,Y)坐标处。 如果你觉得这听起来有点乱,不用担心,稍后我将会举一个浅显易懂的例子,但在此之前,让我们先来看看什么是内核: 上面我们定义了一个3×3的内核(猜猜这个内核可以用来做什么?) 内核可以是M×N的任意大小,但M和N必须是奇整数。 注意:很多常见的内核都是N×N大小的方形矩阵。 我们使用奇数尺寸的内核,是为了保证在图像的中心,(X,Y)坐标是有效的: 上图中左边是一个3×3的矩阵。若矩阵的左上角为原点,且坐标是零索引的,那么,很显然,矩阵的中心位于(1,1)坐标处。而右边的2×2矩阵,其中心位于(0.5,0.5)处。但是,如我们所知,除非使用插值,否则不可能出现(0.5,0.5)这样的像素坐标,也就是说,我们的像素坐标必须是整数!这也就是为什么我们必须用奇数的内核尺寸的原因。 卷积 现在,我们已经基本了解了什么是内核,再来看看卷积吧。 在图像处理中,卷积需要三个元素: 一幅输入图像 一个内核矩阵(将与输入图像做卷积) 一幅输出图像(用于存储输入图像与内核卷积的结果) 卷积其实非常的简单。我们只需要: 从原始图像中选取一个(X,Y)坐标 将内核的中心点放到(X,Y)坐标处 输入图像中与内核重叠区域,与内核逐元素相乘,然后将这些乘法运算的值累加得到一个单一的值。这些乘积的总和称为内核输出 将步骤3获得的结果存储在输出图像中,存储位置与步骤1中的(X,Y)坐标相同 下面是一个卷积的例子,用之前定义的3 x 3大小内核对一幅图像的3 x 3区域进行模糊处理: 因此: 卷积之后,我们把输出结果 Oi,j = 126 存储到输出图像的(i,j)坐标处。 这一切就是这么简单! 卷积其实就是内核与输入图像中内核覆盖区域之间逐像素的乘积和。 用OpenCV和Python实践卷积 之前我们已经做了有关内核和卷积的有趣讨论。现在让我们去看一些代码,来了解一下内核和卷积是怎样被实现的。这些源代码也会对你了解卷积如何应用于图像处理有所帮助。 首先,打开一个新文件,将其命名为convolutions.py,写入以下内容: 第2-5行导入一些必要的Python包。你的系统上应该已经安装了NumPy和OpenCV,但你可能没有安装scikit-image。只需用pip就可完成安装: ? 1 $ pip install -U scikit-image 接下来,我们就可以定义卷积了 卷积函数convolve有两个输入参数:灰度图像image和内核kernel。 在第10和11行,分别获取了image和kernel的尺寸(宽和高)。 在继续之前,理解内核kernel滑动经过原始图像image的每一个像素点,逐点进行卷积运算,并将卷积结果存储到一幅输出图像相应位置的这一过程是很重要的。 为什么呢?[…]